
一、为什么要用分布式ID?
1. 什么情况下我们需要ID生成器
- 数据库水平拆分的情况下,主键由于需要作为业务标识使用,需要唯一。
- 业务编号需要暴露给用户,但是又不想被用户猜到需要被隐藏的业务编号
- 业务编号需要体现业务信息,比如订单分类订单渠道等等 拿MySQL数据库举个栗子: 在我们业务数据量不大的时候,单库单表完全可以支撑现有业务,数据再大一点搞个MySQL主从同步读写分离也能对付。 但随着数据日渐增长,主从同步也扛不住了,就需要对数据库进行分库分表,但分库分表后需要有一个唯一ID来标识一条数据,数据库的自增ID显然不能满足需求;特别一点的如订单、优惠券也都需要有唯一ID做标识。此时一个能够生成全局唯一ID的系统是非常必要的。那么这个全局唯一ID就叫分布式ID。
2. ID生成器设计目标
- 全局唯一:必须保证ID是全局性唯一的,基本要求
- 高性能:高可用低延时,ID生成响应要块,否则反倒会成为业务瓶颈
- 高可用:100%的可用性是骗人的,但是也要无限接近于100%的可用性
- 好接入:要秉着拿来即用的设计原则,在系统设计和实现上要尽可能的简单
- 趋势递增:最好趋势递增,这个要求就得看具体业务场景了,一般不严格要求
二、常见ID生成方案
1、基于UUID
UUID 是 通用唯一识别码(Universally Unique Identifier)的缩写,是一种软件建构的标准,亦为开放软件基金会组织在分布式计算环境领域的一部分
UUID是由一组32位数的16进制数字所构成,是故UUID理论上的总数为1632=2128,约等于3.4 x 1038。也就是说若每纳秒产生1兆个UUID,要花100亿年才会将所有UUID用完。
UUID的标准型式包含32个16进制数字,以连字号分为五段,形式为8-4-4-4-12的32个字符。示例: 550e8400-e29b-41d4-a716-446655440000
每秒产生10亿笔UUID,100年后只产生一次重复的机率是50%
1 | public static void main(String[] args) { |
优点:
- 本地生成,没有网络消耗
- 可以任意水平扩展
- 生成效率高
- 生成节点不限
缺点
- 没有排序,无法保证趋势递增。
- UUID往往是使用字符串存储,查询的效率比较低。
- 存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。
- 传输数据量大
- 不可读
可以使用,但是并不推荐!
2、数据库自增列
可以通过设置bigint类型的数据库自增列,在事务中通过Insert操作获取主键Id
基于数据库的auto_increment自增ID完全可以充当分布式ID,具体实现:需要一个单独的MySQL实例用来生成ID,建表结构如下:
1 | CREATE DATABASE `SEQ_ID`; |
1 | insert into SEQUENCE_ID(value) VALUES ('values'); |
当我们需要一个ID的时候,向表中插入一条记录返回主键ID,但这种方式有一个比较致命的缺点,访问量激增时MySQL本身就是系统的瓶颈,用它来实现分布式服务风险比较大,不推荐!
优点
- 可以实现ID完全递增
- 部署简单,有DB就可以
缺点 - 生成效率差,取决于数据库性能指标,每秒生成一万ID都很难
- 依赖于数据库,如果DB发生故障,在做主从切换的时候可能会引发BUG
3、Redis生成ID
当使用数据库来生成ID性能不够要求的时候,我们可以尝试使用Redis来生成ID。这主要依赖于Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:
A:1,6,11,16,21
B:2,7,12,17,22
C:3,8,13,18,23
D:4,9,14,19,24
E:5,10,15,20,25
这个,随便负载到哪个机确定好,未来很难做修改。但是3-5台服务器基本能够满足器上,都可以获得不同的ID。但是步长和初始值一定需要事先需要了。使用Redis集群也可以方式单点故障的问题。
另外,比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。
用redis实现需要注意一点,要考虑到redis持久化的问题。redis有两种持久化方式RDB和AOF:
- RDB会定时打一个快照进行持久化,假如连续自增但redis没及时持久化,而这会Redis挂掉了,重启Redis后会出现ID重复的情况。
- AOF会对每条写命令进行持久化,即使Redis挂掉了也不会出现ID重复的情况,但由于incr命令的特殊性,会导致Redis重启恢复的数据时间过长。
4、MongoDB的ObjectId
MongoDB的ObjectId和snowflake算法类似。它设计成轻量型的,不同的机器都能用全局唯一的同种方法方便地生成它。MongoDB 从一开始就设计用来作为分布式数据库,处理多个节点是一个核心要求。使其在分片环境中要容易生成得多。
其格式如下:
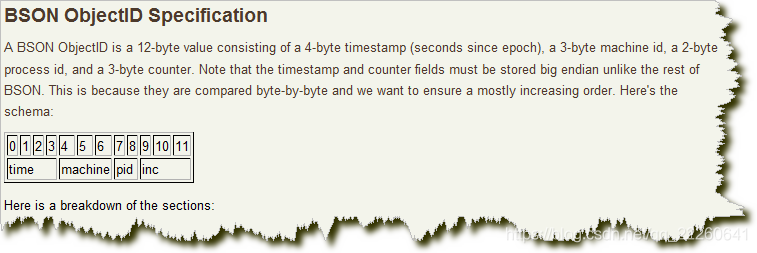
前4 个字节是从标准纪元开始的时间戳,单位为秒。时间戳,与随后的5 个字节组合起来,提供了秒级别的唯一性。由于时间戳在前,这意味着ObjectId 大致会按照插入的顺序排列。这对于某些方面很有用,如将其作为索引提高效率。这4 个字节也隐含了文档创建的时间。绝大多数客户端类库都会公开一个方法从ObjectId 获取这个信息。
接下来的3 字节是所在主机的唯一标识符。通常是机器主机名的散列值。这样就可以确保不同主机生成不同的ObjectId,不产生冲突。
为了确保在同一台机器上并发的多个进程产生的ObjectId 是唯一的,接下来的两字节来自产生ObjectId 的进程标识符(PID)。
前9 字节保证了同一秒钟不同机器不同进程产生的ObjectId 是唯一的。后3 字节就是一个自动增加的计数器,确保相同进程同一秒产生的ObjectId 也是不一样的。同一秒钟最多允许每个进程拥有2563(16 777 216)个不同的ObjectId。
5、基于数据库的号段模式
号段模式是当下分布式ID生成器的主流实现方式之一,号段模式可以理解为从数据库批量的获取自增ID,每次从数据库取出一个号段范围,例如 (1,1000] 代表1000个ID,具体的业务服务将本号段,生成1~1000的自增ID并加载到内存。表结构如下:
1 | CREATE TABLE id_generator ( |
biz_type :代表不同业务类型
max_id :当前最大的可用id
step :代表号段的长度
version :是一个乐观锁,每次都更新version,保证并发时数据的正确性
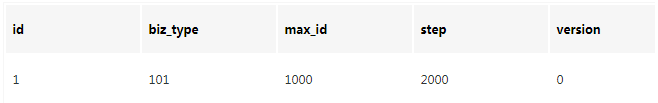
等这批号段ID用完,再次向数据库申请新号段,对max_id字段做一次update操作,update max_id= max_id + step,update成功则说明新号段获取成功,新的号段范围是(max_id ,max_id +step]。
1 | update id_generator set max_id = #{max_id+step}, version = version + 1 where version = # {version} and biz_type = XXX |
由于多业务端可能同时操作,所以采用版本号version乐观锁方式更新,这种分布式ID生成方式不强依赖于数据库,不会频繁的访问数据库,对数据库的压力小很多。
6、Twitter的雪花算法(Snowflake)snowflake算法
雪花算法(Snowflake)是twitter公司内部分布式项目采用的ID生成算法,开源后广受国内大厂的好评,在该算法影响下各大公司相继开发出各具特色的分布式生成器。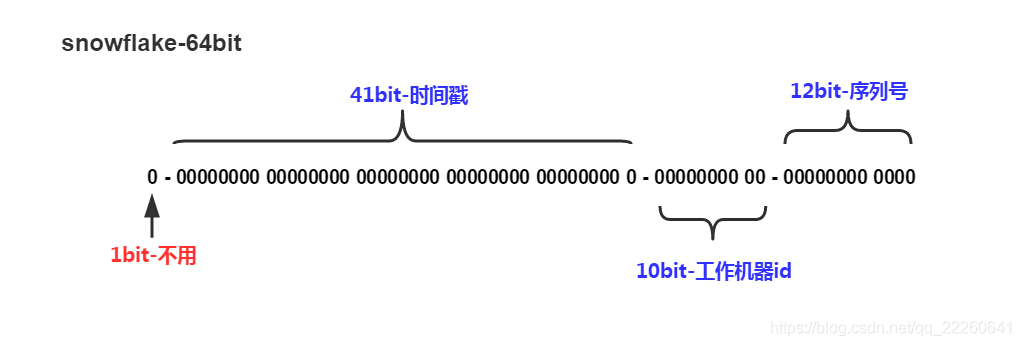
Snowflake生成的是Long类型的ID,一个Long类型占8个字节,每个字节占8比特,也就是说一个Long类型占64个比特。
Snowflake ID组成结构:正数位(占1比特)+ 时间戳(占41比特)+ 机器ID(占5比特)+ 数据中心(占5比特)+ 自增值(占12比特),总共64比特组成的一个Long类型。

Java版本的Snowflake算法实现:
1 | public class SnowFlakeShortUrl { |
理论上单机每秒400W+,最多每秒可以生成41亿+的ID
优点
- ID趋势递增
- 生成效率高,单机每秒400W+
- 支持线性扩充
- 稳定性高,不依赖DB等服务
缺点 - 依赖服务器时间,如果服务器时间发生回拨,可能导致生成重复ID
- 在单机上是递增的,但是由于涉及到分布式环境,每台机器上的时钟不可能完全同步,也许有时候也会出现不是全局递增的情况
总结
个人建议,并发不大项目较小的可以简单的使用Redis生成ID的方式,但如果后续项目有可能比较大的增长空间或者项目并发较大的项目建议使用最后的Snowflake算法或者其他适合的方式
关注Github:1/2极客
关注博客:御前提笔小书童
关注网站:HuMingfeng
关注公众号:开发者的花花世界

本作品采用知识共享署名 4.0 中国大陆许可协议进行许可,欢迎转载,但转载请注明来自御前提笔小书童,并保持转载后文章内容的完整。本人保留所有版权相关权利。

